In the first part of this project, we used Mechanize to collect surgery cost data for every California hospital, by county, category of procedure, and type of procedure. All together, we collected about 4,500 HTML files (which you can download here if you skipped the last part).
Now we parse the files for the data to store in a database. Since these files are raw HTML, we are performing a web-scrape and parsing the HTML for the exact fields that we want.
The resulting datafiles, in SQLite and plaintext, are here for download.
The Steps
This phase of the project involves the following steps:
- Parse the HTML – Use Nokogiri to read the HTML files and scrape the data from the HTML tables.
- Store the data – Save the data into a SQLite database to make them easier to query.
There's no reason that this parsing and storing phase couldn't be combined with the HTML-fetching script from the previous section. But now that all the HTML files are stored locally, we can test out parsing scripts on them and quickly see the results.
Parsing with Nokogiri
By now, examining a webpage's structure with a web inspector such as Firebug should be a familiar process to you.
Open any of the HTML files we pulled from the Common Surgeries database:
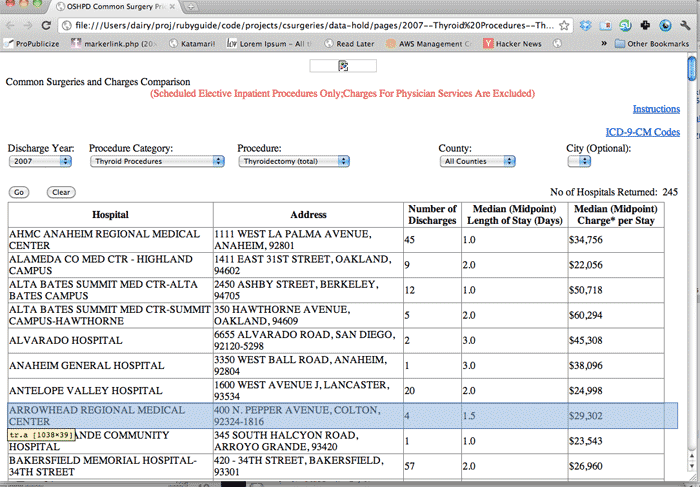
Inspect the table element:

It looks like the table has an id of ctl00_ContentPlaceHolder1_gridHospitalList. The first table row element contains headers, the last one contains the number of hospitals in the table. Everything in between is actual data.
The CSS selector to capture those table row elements is:
#ctl00_ContentPlaceHolder1_gridHospitalList tr
Then it's just a matter of splitting each <tr> element into table cells and converting their contents to text:
page = Nokogiri::HTML(open(fname))
page.css("#ctl00_ContentPlaceHolder1_gridHospitalList tr")[1..-2].each do |tr|
puts tr.css('td').map{ |td|
td.text.gsub(/[$,](?=\d)/, '').gsub(/\302\240|\s/, ' ').strip
}.join(" | ")
end
#=> ALVARADO HOSPITAL | 6655 ALVARADO ROAD, SAN DIEGO, 92120-5298 | 2 | 3.0 | 45308
Those two gsub calls look more intimidating than they are. The first one uses a regular expression to convert currency amounts (e.g. $12,345) to numbers (e.g. 12345). The second one converts any kind of HTML whitespace – including tab and newline characters – into a normal space character, because we don't want to store line breaks in our flat text file.
Parsing the filenames
If you followed the previous part, the HTML files should be named in this format:
2007--Thyroid Procedures--Parathyroidectomy--Yolo.html i.e. YEAR--CATEGORY--PROCEDURE--COUNTY.html
In our database, we want to keep track of these properties. All it takes is splitting the filename by the delimiter "--". We can use the File.basename method to get the filename sans the .html extension and directory name:
year,category,procedure,county = File.basename(fname, '.html').split('--')Looping through
Nothing clever here. Just collect the filenames from whatever directory you stored them in, loop through and parse them. Also, skip the files named "All Counties" so you don't double-count records.
Before we add the data to a database, we can store it all in a flat textfile.
Note: If you get an encoding error, try including #encoding: UTF-8 at the top of the file.
require 'rubygems'
require 'nokogiri'
TABLE_DIV_ID = "#ctl00_ContentPlaceHolder1_gridHospitalList"
FIELD_NAMES = ['year', 'category', 'procedure', 'county', 'hospital', 'address','discharge_count', 'median_length_in_days', 'median_charge_per_stay']
OFILE = File.open('data-hold/data.txt', 'w')
OFILE.puts FIELD_NAMES.join("\t")
Dir.glob("data-hold/pages/*.html").reject{|f| f =~ /All Counties/}.each do |fname|
meta_info = File.basename(fname, '.html').split('--')
page = Nokogiri::HTML(open(fname))
page.css("#{TABLE_DIV_ID} tr")[1..-2].each do |tr|
data_tds = tr.css('td').map{ |td|
td.text.gsub(/[$,](?=\d)/, '').gsub(/\302\240|\s/, ' ').strip
}
OFILE.puts( (meta_info + data_tds).join("\t"))
end
end
OFILE.close
Storing the Data with SQLite
If you haven't read the chapter on SQL and SQLite, review it now as I won't be explaining the basics here. You should be familiar with the basic syntax, including how to open a database and select rows.
Creating the table
In the previous code section, I defined the FIELD_NAMES constant which contains an array of the field names. It's used to print out the headers for the textfile and we can use it to generate the table schema:
TABLE_NAME = 'surgery_records'
q = "CREATE TABLE #{TABLE_NAME}(#{FIELD_NAMES.map{|f| "`#{f}`"}.join(', ')});"
puts q
That map method simply sets each field name to be enclosed in backticks (which is necessary if you have a field name like "A Hospital's Name" with non-alphanumeric characters)
CREATE TABLE surgery_records(`year`, `category`, `procedure`, `county`, `hospital`, `address`, `discharge_count`, `median_length_in_days`, `median_charge_per_stay`)
Specify column types
As with other variants of SQL, SQLite allows you to specify a datatype per column. It is helpful to specify that a column of data is supposed to be all numbers so that that column's data is treated as numbers when doing comparisons. Remember:
| Numbers | Strings |
|---|---|
| 11 > 9 | "11" < "9" |
Turning FIELD_NAMES into a two-dimensional array allows us to modify the query string used to create the table in the following fashion:
FIELD_NAMES = [['year', 'NUMERIC'],['category', 'VARCHAR'], ['procedure', 'VARCHAR'],['county', 'VARCHAR'], ['hospital', 'VARCHAR'], ['address', 'VARCHAR'], ['discharge_count', 'NUMERIC'], ['median_length_in_days', 'NUMERIC'], ['median_charge_per_stay', 'NUMERIC'] ]
q= "CREATE TABLE #{TABLE_NAME}(#{FIELD_NAMES.map{|f| "`#{f[0]}` #{f[1]}"}.join(', ')});"
puts q
#=> CREATE TABLE surgery_records(`year` NUMERIC, `category` VARCHAR, `procedure` VARCHAR, `county` VARCHAR, `hospital` VARCHAR, `address` VARCHAR, `discharge_count` NUMERIC, `median_length_in_days` NUMERIC, `median_charge_per_stay` NUMERIC);
Create column indexes
For large datasets, you can greatly speed up your queries by indexing the columns that you intend to do "WHERE column_a = `dog`" conditions. For the Common Surgeries data, we will be aggregating numbers per procedure, county, and hospital, so it makes sense to index those.
Even though we will also SELECT rows based on specific year values. But since there are only 3 possible values – 2007, 2008, and 2009 – in this dataset, the performance gain from indexing would be minimal, if any.
Read more about indexing database tables here.
In the FIELD_NAMES array, we can add a third value per field that represents the We can add to. If that third value is present, we create an index for that field. If not, we don't create an index. The actual index name isn't important, nor will you need to remember it while doing queries. The SQLite engine will use the index automatically:
FIELD_NAMES = [['year', 'NUMERIC'],['category', 'VARCHAR'], ['procedure', 'VARCHAR', 'procedure_index' ],['county', 'VARCHAR', 'county_index'], ['hospital', 'VARCHAR', 'hospital_index'], ['address', 'VARCHAR'], ['discharge_count', 'NUMERIC'], ['median_length_in_days', 'NUMERIC'], ['median_charge_per_stay', 'NUMERIC'] ]
FIELD_NAMES.each do |fn|
puts "CREATE INDEX #{fn[2]} ON #{TABLE_NAME}(#{fn[0]})" unless fn[2].nil?
end
#=> CREATE INDEX procedure_index ON surgery_records(procedure)
#=> CREATE INDEX county_index ON surgery_records(county)
#=> CREATE INDEX hospital_index ON surgery_records(hospital)
The INSERT statement
This is the INSERT statement for loading our data:
DB_INSERT_STATEMENT = "INSERT into #{TABLE_NAME} values (#{FIELD_NAMES.map{'?'}.join(',')})"
puts DB_INSERT_STATEMENT #=> "INSERT into surgery_records values (?,?,?,?,?,?,?,?,?)"
Those question marks will be filled in with the values we specify once we actually execute the INSERT statement. How does SQLite know which value goes into which column? Since we don't specify anything, it simply inserts the values in sequential order, i.e. the value in the first ? will be inserted in the first column of the table.
As long as we specify the data in the same order of the table's column structure, we will be good to go. Luckily, we prepared in advance by creating the table columns with the FIELD_NAMES array. We use that array again when entering the actual data.
Providing the values for the INSERT statement is as simple as passing in an array of values to the SQLite instance's execute method:
DB.execute(DB_INSERT_STATEMENT, some_array_of_values)
Storage code, all together
I've made a few iterations on the code and its variables as we progressed in this chapter. Here's the final code; on my laptop, it completed the scraping and database loading in under a minute:
require 'rubygems'
require 'nokogiri'
require 'sqlite3'
FIELD_NAMES = [['year', 'NUMERIC'],['category', 'VARCHAR'], ['procedure', 'VARCHAR', 'procedure_index' ],['county', 'VARCHAR', 'county_index'], ['hospital', 'VARCHAR', 'hospital_index'], ['address', 'VARCHAR'], ['discharge_count', 'NUMERIC'], ['median_length_in_days', 'NUMERIC'], ['median_charge_per_stay', 'NUMERIC'] ]
# Set up scrape and text file
TABLE_DIV_ID = "#ctl00_ContentPlaceHolder1_gridHospitalList"
OFILE = File.open('data-hold/ca-common-surgeries.txt', 'w')
OFILE.puts( FIELD_NAMES.map{|f| f[0]}.join("\t") )
# Set up database; delete existing sqlite file
DBNAME = "data-hold/ca-common-surgeries.sqlite"
File.delete(DBNAME) if File.exists?DBNAME
DB = SQLite3::Database.new( DBNAME )
TABLE_NAME = "surgery_records"
DB_INSERT_STATEMENT = "INSERT into #{TABLE_NAME} values
(#{FIELD_NAMES.map{'?'}.join(',')})"
# Create table
DB.execute "CREATE TABLE #{TABLE_NAME}(#{FIELD_NAMES.map{|f| "`#{f[0]}` #{f[1]}"}.join(', ')});"
FIELD_NAMES.each do |fn|
DB.execute "CREATE INDEX #{fn[2]} ON #{TABLE_NAME}(#{fn[0]})" unless fn[2].nil?
end
Dir.glob("data-hold/pages/*.html").reject{|f| f =~ /All Counties/}.each do |fname|
meta_info = File.basename(fname, '.html').split('--')
page = Nokogiri::HTML(open(fname))
page.css("#{TABLE_DIV_ID} tr")[1..-2].each do |tr|
data_tds = tr.css('td').map{ |td|
td.text.gsub(/[$,](?=\d)/, '').gsub(/\302\240|\s/, ' ').strip
}
data_row = meta_info + data_tds
OFILE.puts( data_row.join("\t"))
DB.execute(DB_INSERT_STATEMENT, data_row)
end
end
OFILE.close
Code Comparison: SQL vs. Ruby
Was it worth all that work to create a SQLite database for records that are easily stored in a textfile? For this relatively small set (20,000+ rows), it may come down to a matter of preference. But for datasets with rows numbering in the hundreds of thousands or even millions, a database is probably the only way to efficiently handle the data.
Learning SQL – especially if you're just learning programming, period – is intimidating. But knowing how to construct even simple statements can save you time and frustration later on. SQL isn't the only database solution, but the basics of how database software meshes with scripting code is the same across SQL and non-SQL solutions.
The following section contains a few sample queries on the SQLite database compared to the pure Ruby code needed to get the same results with a textfile loaded as an array of tab-delimited rows.
Note: I've added line breaks so that more code is visible within the narrow table cells.
| SQL database | Ruby collection |
|---|---|
| Setup | |
|
|
| Count number of rows | |
|
|
| Total number of discharges | |
|
|
| Total number of records by procedure | |
This returns an array of arrays: [['PROCEDURE_NAME', 'PROCEDURE_COUNT]] |
This creates a hash with the procedure names as the index: hash{'PROCEDURE_NAME'} = PROCEDURE_COUNT
|
|
Select and order rows, with conditions
The most common queries will involve gathering records that meet certain conditions, such as having a county of "Los Angeles" and a year of "2008". And in some cases, you'll want them ordered by a certain value. | |
|
|
Considering SQL versus Ruby collections
To a SQL novice, the SQLite query reads like plain – albeit, somewhat-broken English – and is easy to comprehend even if you knew nothing about this particular dataset. In the text-array version, you have to decipher several boolean statements and a sequence of methods.
So is the extra work of learning SQL and creating a database worth it? As in most things about programming, it's a pain at first, but saves you much greater pain in the future. Besides writing a chapter on SQL, I use SQL for most of the data-intensive projects included in this book.
If you had trouble creating the database from the last chapter, you can download a copy of the data I compiled here (includes both SQLite and plaintext).