
"good coders code, great reuse"
Even this early on, we'll learn how to put together useful code with very little actual coding ourselves. This is because of methods, which allow us to invoke other programmer's code with a single word.
The puts command that we've been using to print results is itself a method:
puts "hello"
#=> helloThis chapter will teach the basics of method construction and use. The next chapter covers the practical uses of methods. As with any powerful tool, Ruby methods and libraries have instruction manuals that you'll need to at least skim. If you want to be a better programmer, though, reading others' code is a great way to start.
Hello again, "Hello World"
That first script you put together seemed so easy, right?
puts "Hello World" #=> Hello World
Printing a "string" to the screen seems easy because the puts method hides all the necessary code from you. But the underlying details are complicated. Take a look at the source code behind puts:
VALUE
rb_io_puts(int argc, VALUE *argv, VALUE out)
{
int i;
VALUE line;
/* if no argument given, print newline. */
if (argc == 0) {
rb_io_write(out, rb_default_rs);
return Qnil;
}
for (i=0; i<argc; i++) {
if (TYPE(argv[i]) == T_STRING) {
line = argv[i];
goto string;
}
line = rb_check_array_type(argv[i]);
if (!NIL_P(line)) {
rb_exec_recursive(io_puts_ary, line, out);
continue;
}
line = rb_obj_as_string(argv[i]);
string:
rb_io_write(out, line);
if (RSTRING_LEN(line) == 0 ||
!str_end_with_asciichar(line, '\n')) {
rb_io_write(out, rb_default_rs);
}
}
return Qnil;
}
All of that was encapsulated into a single word: puts. As you'll see throughout this book, much more powerful tasks and routines can be invoked with a single word. Someday you may write your own methods for others to use. Until then, you can pretty much build a career from the diligence of countless other programmers.
Another reason why it's nice to use Ruby to learn programming: compare its "Hello World" to equivalent scripts in other languages.
Anatomy of a method
Hell, let's just write our own method now. It's the best way to understand how methods work.
def embiggen(str)
str = "#{str}!!!"
str = str.upcase
return str
end
puts( embiggen('hello world') )
#=> HELLO WORLD!!!
So this embiggen method takes in a string and returns a capitalized version of that string with exclamation marks added to the end. Let's break it down:
- def
- This keyword tells the Ruby interpreter that we're defining a method. The next word is the name of the method.
- embiggen
- This is what I've arbitrarily decided to name the method. The naming rules are pretty much the same as they are for variables: stick to lowercase letter and underscores.
- (str)
- The terms inside the parentheses are arguments, which stand for the values we want to pass into the method. Multiple arguments are separated with commas.
- upcase
- This is another String method that is capitalizes a string. Yes, this means that methods can be used within other methods.
- return
- This Ruby keyword indicates what object this method returns, if anything
- end
- This marks the end of the method definition.
That was a word-by-word breakdown of our embiggen method. Here's the general components of a method definition:
- The name – how you will refer to the method. The naming convention and rules are similar to the ones I mentioned for variables (i.e. stick to lowercase letters and underscores).
- The arguments – these are the variables, if any, that the method will use or operate on. When calling the method, you must pass in the same number of arguments as listed in the method definition (unless they are defined as optional).
- The block – the chunk of code that does something
The return value – is what the method passes back to whatever called it – you can think of it as the method's answer. In the case of our embiggen method, it is the variable str, which has been set equal to a capitalized, excited version of itself. Generally, a method automatically returns the value of its last line.
What does puts return?
If you've used the puts method inside of irb, then you've probably noticed output such as this:
ruby-1.8.7-p330 :001 > puts "hello world" hello world => nil ruby-1.8.7-p330 :002 >
Line 1 is where I invoke the puts method. The second line is the result – but not the return value – of the puts method, which is outputting to screen the string I passed ito it ("hello world").
Line 3 is where irb returns the return value of puts: nil. This is Ruby's word for nothing, which even more empty of existence than 0 or an empty string "".
So while the method puts prints something to screen while executing its code block, it itself doesn't give back any value at the end of its execution.
Premature returns
What happens if you call return before the final line of a method? The Ruby interpreter will exit out of the method before it gets to that final line. We'll learn about non-linear scripts in upcoming if/else conditional branches chapter.
def my_foo(a,b)
a * b - 42
end
def my_foo2(a,b)
return a * b - 42
end
def my_foo3(a,b)
return "Nada"
a * b - 42
end
puts my_foo(1,2)
#=> -40
puts my_foo2(1,2)
#=> -40
puts my_foo3(1,2)
#=> Nada
Exercise: Arguments and return
Write a method that:
- Accepts two strings as arguments
- Outputs to screen a string that consists of the two strings concatenated and capitalized
- The method should return only the second string
Solution
def foo(str1, str2)
puts "#{str1}{str2}".capitalize
str2
end
Notice that I've omitted the return keyword. By default, if there is no other point of exit in the method, the value of the last line will be the method's return value. This is not the case in other languages, as I often forget.
Scope
As I'll admit again and again, I'm breezing past important computer science concepts that can be explored thoroughly later. Variable scope is one such concept. It's the concept that variables only exist in the context in which they are declared.
For instance, say you define a variable inside of a method:
def foo(var_of_limited_scope)
puts "#{var_of_limited_scope} is inside method foo"
end
The variable var_of_limited_scope is used inside of foo to refer to the method's single argument:
def foo(var_of_limited_scope)
puts "#{var_of_limited_scope} is inside method foo"
end
foo("hello world")
#=> hello world is inside method foo
However, you are not allowed to reference var_of_limited_scope anywhere outside of the scope of foo. This will cause an error:
def foo(var_of_limited_scope)
puts "#{var_of_limited_scope} is inside method foo"
end
foo("hello world")
#=> hello world is inside method foo
puts var_of_limited_scope
#=> NameError: undefined local variable or method `var_of_limited_scope'
Moreover, the method foo itself is unaware of variables that have been declared outside of its definition:
some_var = 42
def foo(var_of_limited_scope)
puts "#{var_of_limited_scope} is inside method foo. #{some_var} is not"
end
foo("test")
#=> NameError: undefined local variable or method `some_var'
To emphasize the point further, foo is ignorant of externally defined variables even if they have the same name as variables defined inside of foo:
var_of_limited_scope = 42
puts var_of_limited_scope
#=> 42
def foo(var_of_limited_scope)
puts "#{var_of_limited_scope} is inside method foo."
end
foo "FORTY TWO
#=> FORTY TWO is inside method foo.
The present discussion ignores the existence of global, class, and instance variables, all of which are not quite as limited in scope. We'll cross that bridge when we get there.
Exercise: Decipher scope
Predict the following output of this code snippet:
x = 'xylophone'
y = 'yoyo'
def fooz(a,b)
x = 'zebra'
"#{a}, played by #{x}, watched by #{b}"
end
a = 'owl'
puts "#{fooz(x,a)} --> #{fooz(a,y)}"
Solution
xylophone, played by zebra, watched by owl --> owl, played by zebra, watched by yoyo
Exercise: Method practice
Just to make sure you understand the basics of method design. Write a method:
- Named triple_adder
- Takes three arguments
- Adds them together with an exclamation mark at the end
Solution
def triple_add(a, b, c)
x = a.to_s + b.to_s + c.to_s
"#{x}!"
end
A more condensed version:
def triple_add(a, b, c)
"#{a.to_s + b.to_s + c.to_s}!"
endThis was a bit of a sloppy exercise because I didn't tell you how exactly I wanted you to add those three variables. If you passed three numbers (Fixnum) into the above implementation of triple_add:
puts triple_add(1,2,5) # "125!"
Why is the result not "8!"? In fact, why is the result a String?
The second question is easier: the return value of triple_add is a quoted String. That's how the exclamation mark gets added to the end.
And so to answer the first question: the three values passed in – 1, 2, and 5 – were converted to "1", "2", and "5" because I called the method to_s on them. I briefly mentioned to_s in the String lesson: it converts data – in this case, numbers – into Strings. So, we are no longer doing arithmetic, but string concatenation.
Remember that you (usually) can't add different datatypes together.
Thus, this implementation and invocation of triple_add would result in an error if the arguments are not all of the same class:
def triple_add(a, b, c)
"#{a + b + c}!"
end
triple_add(1,2,"three")
#=> TypeError: String can't be coerced into Fixnum
The use of to_s converts all the arguments into strings, so a user can pass any type of argument in and triple_add won't crash.
But this conflict-averse approach isn't necessarily wise. What if you want an error to be thrown, because if someone is passing in mixed data types, they are using it wrong? There's a whole area in programming – exception handling – that concerns itself with how programs should react and/or carry on when encountering errors.
My use of to_s happily accepts just about any datatype and comes up with a return value, without indicating to the user that it may not be the answer he/she really wants. This kind of silent failure is often an undesirable, catastrophic approach for a program, like having an accountant who "fixes" the expenditure reports to avoid showing a negative cash flow.
Method design
This section is a last-minute addition to this chapter. It's difficult to demonstrate the finer points of method design at this junction because their effects are much more obvious after knowing about conditional branches and loops. But I think we know enough to at least consider methods from a big picture standpoint.
Keeping your code DRY
DRY is simply the acronym for "Don't repeat yourself."
This is a fundamental design principle for programming because not having to do tasks (including writing code) over and over is one of the main reasons to learn programming.
As we've seen so far, methods is a great example of this concept. Instead of having to copy and paste the source code for puts every time we want to print out to screen, we just invoke puts itself:
puts "Hello world"As you start to write programs, there will be tasks that you'll find yourself doing over and over. So, write a method that wraps all the steps into a single word. As you get better at coding, you'll start to see patterns in your tasks. You will see that some tasks may not be exactly the same but you can generalize the steps enough that you can write a method that handles all these similar cases.
DRYing your code involves (at least) these two concepts: abstraction and modularity. Let's see how these concepts are implemented in a real program.
Counting images on the New York Times homepage
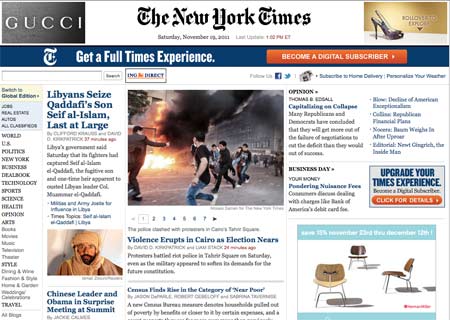
Let's say you want to analyze how many images are on www.nytimes.com at a given moment. You could load up the page and count it by hand. Or you could write a short script to download the page and count the number of HTML tags used for images.
If you know nothing about HTML, at least know this: it's made up of tags. A typical HTML tag consists of a lowercase word surrounded by angle brackets. This, for example, is the HTML tag that denotes an image:
<img>
With image tags, there's usually attributes that are also inside the angle brackets. The following HTML tag would display an image at the URL specified by the src attribute:
<img src="http://ruby.bastardsbook.com/files/dog.jpg">
That raw HTML will be rendered in the browser as:

There's more to it, but that's all we need to know. The following code snippet will be unfamiliar to you, but it involves invoking other methods to count the number of occurrences that begin with "<img"
require "open-uri"
url = "http://www.nytimes.com"
pattern = "<img"
page = open(url).read
tags = page.scan(pattern)
puts "The site #{url} has #{tags.length} img tags"
The output:
The site http://www.nytimes.com has 78 img tags
Repeating ourselves
How do we do this for another newspaper? We could just copy the code above and change the url variable:
require "open-uri"
url = "http://www.bostonglobe.com"
pattern = "<img"
page = open(url).read
tags = page.scan(pattern)
puts "The site #{url} has #{tags.length} img tags"
But that's a direct violation of DRY: all the steps are the same except for the value of url. So instead, let's write a method that takes in a string for url and then does all the other steps:
require "open-uri"
def count_image_tags(url)
pattern = "<img"
page = open(url).read
tags = page.scan(pattern)
puts "The site #{url} has #{tags.length} img tags"
endcount_image_tags("http://www.wsj.com", "WSJ", "div")Here's how to use it:
count_image_tagsThe output:
The site http://www.bostonglobe.com has 45 img tags
Abstraction
What if we want to do more than just image tags?
We could write method like this:
require "open-uri"
def count_div_tags(url)
pattern = "<div"
page = open(url).read
tags = page.scan(pattern)
puts "The site #{url} has #{tags.length} div tags"
end
But again, that violates DRY – because the only thing different is the value of pattern.
So let's make the counting method more generalized. This requires a slight redesign so that the method now takes in two arguments: the site url and the desired tag:
require "open-uri"
def count_any_tags(url, tag)
pattern = /<#{tag}\b/
page = open(url).read
tags = page.scan(pattern)
puts "The site #{url} has #{tags.length} #{tag} tags"
endHere's how to use it:
count_any_tags("http://www.wsj.com", "div")The output:
The site at http://www.wsj.com has 493 div tags
Using a loop
Let's now reap the fruits of our abstraction. I'll use two things we haven't covered yet – loops and collections – to show how this generalized method can be used repeatedly with ease. The variable tags holds a collection of strings. And we use the each method to loop through each string and invoke the count_any_tags method:
url = "http://www.nytimes.com"
tags = ["a", "div", "img"]
tags.each do |tag|
count_any_tags(url, tag)
end
endThe output:
The site http://www.nytimes.com has 428 a tags The site http://www.nytimes.com has 295 div tags The site http://www.nytimes.com has 79 img tags
So even without knowing about loops, you should see how nice it is to have a nice, flexible wrapper that allows us to count any number of tags with minimal code.
Modularity
There's one major flaw with our implementation so far: every call of count_any_tags invokes the open method (which we cover in detail later in this chapter), which downloads the given URL. So the above loop downloads the NYT's homepage three separate times just to count the three different tags.
Seems wasteful, right? Why not download the page once, store it in a variable, and then count the tags from there?
Because we wrapped up the downloading and counting functions into a single method: count_any_tags:
require "open-uri"
def count_any_tags(url, tag)
pattern = /<#{tag}\b/
page = open(url).read
tags = page.scan(pattern)
puts "The site #{url} has #{tags.length} #{tag} tags"
endKeep it simple
The writing and use of methods is fairly easy. But knowing how to design clean methods is one of the things that separates the good from the lesser programmers.
There's no one absolute principle that defines clean. But the easiest to keep in mind is to keep things simple.
Look at how we named the method: count_any_tags. It does count the tags, of course, but it also downloads the page and prints out a message to screen.
Let's rewrite it so that all it does is count. What arguments does this method need? Well, the downloaded page. And of course, the tag to count. So this rewritten method will take in those two arguments.
def just_count_tags(page, tag)
pattern = /<#{tag}\b/
tags = page.scan(pattern)
return tags.length
endYou may have also noticed that the puts statement is gone. This method just counts tags, does it need to print to screen?. To be more reusable, it should just return the number of tags. Let the program that invokes the method decide how it wants to print the number.
We still need a method to actually download the page. So let's write a new method that just takes in the URL as one argument and returns the contents of the downloaded page:
require 'open-uri'
def fetch_page(url)
return open(url).read
end
I present below an example of how to call the new methods, but I've added one more loop so that multiple websites are examined for multiple kinds of tags.
require 'open-uri'
def just_fetch_page(url)
return open(url).read
end
def just_count_tags(page, tag)
pattern = /<#{tag}\b/
tags = page.scan(pattern)
return tags.length
end
sites = [ "http://www.wsj.com", "http://www.nytimes.com", "http://www.ft.com" ]
tags = ["div","h1","h2","h3","img","p"]
sites.each do |url|
puts "#{url} has:"
tags.each do |tag|
page = just_fetch_page(url)
tag_count = just_count_tags(page, tag)
puts "\t - #{tag_count} <#{tag}> tags"
end
endThe output:
http://www.wsj.com has:
- 489 <div> tags
- 0 <h1> tags
- 130 <h2> tags
- 43 <h3> tags
- 56 <img> tags
- 133 <p> tags
http://www.nytimes.com has:
- 288 <div> tags
- 0 <h1> tags
- 2 <h2> tags
- 8 <h3> tags
- 74 <img> tags
- 45 <p> tags
http://www.ft.com has:
- 100 <div> tags
- 1 <h1> tags
- 1 <h2> tags
- 28 <h3> tags
- 20 <img> tags
- 4 <p> tags
Table of iterations
To review, here is how the tag counting functionality evolved into its abstracted, more modular form:
| No method |
|
| Initial method |
|
| Abstraction |
|
| Modularity |
|
Syntax and shortcuts
Here are a few ways to tighten up your Ruby code. You don't need to use them. As you learn code, it's sometimes better to write it as verbosely as possible. As you get better, you'll appreciate the ways to reduce strain on your typing fingers.
Optional parentheses
When calling a method in other languages, you have to use parentheses to tell the interpreter: "the enclosed values here are the arguments I want to pass in." This is optional in Ruby:
puts "hello world"
puts("hello world")
Chain, chain, chain
You can call methods one after another by using the dot operator on each method's return value.
str = "cat"
str = str.upcase #=> "CAT"
str = str.reverse #=> "TAC"
str = str.capitalize #=> "Tac"
str = "cat".upcase.reverse.capitalize #=> "Tac"
Optional return
The last line in a method is its return value. No need to write return explicitly, unless there are several places where your method can exit out before the last line (we get to this in the conditionals chapter).
def adder(a,b)
c = a + b
return c
end
You don't need the return. In fact, you don't even need the third variable at all:
def adder(a,b)
a+b
end
Caution: Other languages usually require some kind of return statement, even for simple one-line methods. I frequently forget this when switching back and forth between Ruby and Javascript.
Exercise: Simplify the just_count_tags method
From the section on keeping methods simple, rewrite the just_count_tags method so that its body is a single line.
def just_count_tags(page, tag)
pattern = /<#{tag}\b/
tags = page.scan(pattern)
return tags.length
endSolution
def just_count_tags(page, tag)
page.scan(/<#{tag}\b/).length
endExercise: More simplification
Using what we've learned, simplify the following scripts:
def sample_foo(a,b)
a = b.upcase + a
return a
end
def next_foo(one_str, two_str)
return one_str.upcase + two_str.upcase
end
temp_string = "cat".reverse
puts(next_foo(temp_string, "another cat"))
Solution
def sample_foo(a,b)
b.upcase + a
end
def next_foo(one_str, two_str)
one_str.upcase + two_str.upcase
end
puts next_foo "cat".reverse, "another cat"
The code above works. But it's a pain to read because you have to distinguish a comma from a dot. Personally, my brain's initial interpretation of the script is that it puts one long string that is passed into next_foo, as opposed to two strings passed into next_foo, with the result being output to screen
Rather than showing off your brevity, opt for a more readable version:
puts next_foo("cat".reverse, "another cat")
Parentheses and order
Also, parentheses are not just for readability, but they determine order of operations, just as they would in a simple mathematical expression:
1 + (6 * 5) #=> 31
(1 + 6) * 5 #=> 35
def foox(a1, a2)
a1 + a2
end
foox "cat", "dog" #=> "catdog"
foox "pig", foox("cat", "dog") #=> "pigcatdog"
foox "cat", foox "dog", "pig" #=> Syntax error
In that last line, Ruby thinks you're trying something fancier than a nested call of foox and barfs because it is expecting other keywords.
Optional arguments
You must call a method with the same number of arguments as defined in its method definition:
def foo_greeting(recipient)
puts "Hello there, #{recipient.upcase}!"
end
foo_greeting("Bob")
#=> Hello there, BOB!
foo_greeting
#=> ArgumentError: wrong number of arguments (0 for 1)
However, one or more of the arguments can be made optional with the following notation:
def foo_greeting(recipient = "you")
puts "Hello there, #{recipient.upcase}!"
end
foo_greeting
#=> Hello there, YOU!
A good method to know is rand. When called with a number, it generates a random integer between 0 and the number you passed in:
puts rand(10)
#=> 7
puts rand(100)
#=> 34
puts rand(1000)
#=> 472
puts rand(10000)
#=> 8541
However, if you call rand without an argument, it generates a Float between 0 and 1:
puts rand
#=> 0.42940609106596
puts rand
#=> 0.155213416128283
puts rand
#=> 0.777773418756725
More interpretation
What are the outputs of the following method calls?
def foo(a, x)
x + a
end
puts(foo "hot", "dog") #=> ?
def bar(a, x)
foo(a + x).upcase
end
puts bar("hot", "dog").capitalize #=> ?
def foobar(a)
a += a
a = a.reverse
return a
a.upcase
end
puts foobar("cat") #=> ?
Solution
puts(foo "hot", "dog") # "doghot"
puts bar("hot", "dog").capitalize # "DOGHOT"
puts foobar("cat") # "tactac"
In the final output, you may have expected it to be "TACTAC". However, the foobar method returns the value before the final call to upcase.
The open method
In the introductory Tweet-fetching chapter, we used the open method to download webpages from the Internet. We also used open to "open" new files on our hard drive in order to write the webpages to:
require 'open-uri'
url = "http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-3.xml"
remote_page = open(url)
local_file = open("tweets-on-hard-drive.xml", "w")
tweets = remote_page.read
local_file.write(tweets)
local_file.close
It may be a little confusing that open is used in two different contexts. In fact, the open method belongs to two different classes that both map it to the Kernel module (which I'll explain later).
The require keyword is how we tell the Ruby interpreter to include the OpenURI module in the environment. This module provides the specific functionality to let open fetch webpages. Without require 'open-uri', the open method would only be able to open files on the hard drive.
In fact, when opening files just on the hard drive, I'll sometimes include the invoking class, File, to make it more obvious to the reader:
File.open("some-file", "w")So the previous code snippet could also read as:
require 'open-uri'
url = "http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-3.xml"
remote_page = open(url)
local_file = File.open("tweets-on-hard-drive.xml", "w")
tweets = remote_page.read
local_file.write(tweets)
local_file.close
Rewrite concisely
Using what you know about methods and chaining them together, rewrite the webpage-downloading-and-saving script, but with fewer lines.
Solution
You can remove the need for the temporary tweets variable by doing the open and read methods on the same line:
require 'open-uri'
url = "http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-3.xml"
remote_page = open(url).read
local_file = File.open("tweets-on-hard-drive.xml", "w")
local_file.write(remote_page)
local_file.closeOr you can change up the order of operations and eliminate the remote_page variable:
require 'open-uri'
url = "http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-3.xml"
local_file = File.open("tweets-on-hard-drive.xml", "w")
local_file.write(open(url).read)
local_file.closeYou can't, however, compress the File methods:
require 'open-uri'
url = "http://ruby.bastardsbook.com/files/tweet-fetcher/tweets-data/USAGov-tweets-page-3.xml"
File.open("tweets-on-hard-drive.xml", "w").write(open(url).read).closeThe write method returns the number of bytes written, not the file handler. The above code will throw an error.
Finding the destination of a shortened link
Because Twitter messages are limited to 140 characters, links in tweets are usually shortened through a URL shortening service.
So clicking the shortened link:
http://bit.ly/BBoRuby
Will automatically take you here:
http://ruby.bastardsbook.com
This allows for long links to be sent within 140 characters. However, it obscures where the shortened link will actually send you, giving rise to a number of malicious phishing hacks.
The open-uri module condenses the decent-sized chunk of code to download a webpage into the open method. One particular useful feature of open is how it automatically follows redirects. That is, if you use open to open a link that redirects elsewhere, it will automatically go to the new destination.
Let's test it out:
require 'open-uri'
page = open("http://bit.ly/BBoRuby")
puts page.base_uri
#=> http://ruby.bastardsbook.com/
The data object returned by open has a method called base_uri which, when converted to a string, is the page's URL. This is a handy way to see what the final destination of the original link is.
Note: There are faster, more efficient ways to follow redirects and get a page's URL without actually downloading the page. This is just a quick hack using a library we already know.
Methods and classes
This is another last-minute section that takes a shallow dip into the concepts of object-oriented programming. For further discussion, you can check out the chapter on OOP. Also, much of what's discussed here is specific to the Ruby language. This section isn't essential to moving on in the lessons but is useful to know when you start writing your own programs.
The Kernel
We know that numbers and strings each have their own methods invoked by the dot operator:
puts "hello".upcase
#=> HELLOBut how is it that puts doesn't have anything invoking it?
In fact, there is an implicit call from something called Kernel. It's difficult to explain what's going on in detail since so far I've skipped discussion on object-oriented concepts. But for our intents and purposes, Kernel can be thought of as just being there, even without being explicitly called:
puts "Hello world"
#=> Hello world
Kernel.puts "Hello world"
#=> Hello world
myfile = Kernel.open("test.txt", "w")
myfile.puts("hello world")
myfile.close
Kernel also has an open method. Without the require statement for 'open-uri', it can only open local files, not download webpages.
Note that the object myfile has its own puts. In this case, the string is entered into the text file represented by myfile.
Adding methods to an existing class
In the section describing the anatomy of methods, I defined the embiggen method:
def embiggen(str)
str = "#{str}!!!"
str = str.upcase
return str
end
embiggen("Ralph")
#=> "RALPH!!!"
In this context, the embiggen method has been added to Kernel, which you can see if you invoke Kernel.methods:
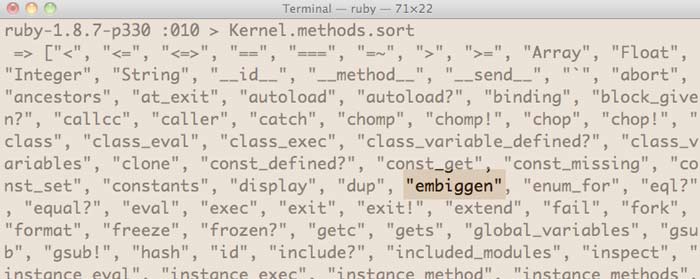
But given that embiggen is intended only for string transformation, it makes more sense to have the method belong to the String class. How do we do this? We make an alteration to the String class.
Think of classes as the blueprints for data objects. One of Ruby's nice features is a programmer can essentially open those blueprints on the fly and make additions or alterations.
So, to add embiggen to the String class:
class String
def embiggen
"#{self.upcase}!!!"
end
end
"Wiggum".embiggen
#=> "WIGGUM!!!"The main takeaways:
- To open up a class definition, you simply start with class CLASS_NAME and close it with end
- Because embiggen is now invoked by a string, there is no need for it to take in an argument.
- How do you specify the invoking object (in embiggen's case, a string)? The keyword self is used to refer to the invoking object.
Exercise: Define a String method for currency
When reading from financial reports, you'll frequently come across numbers expressed in a currency format:
$42 $100,000.12 $98,100
During a program's operation, you'll read these values as strings. To compare and manipulate them as numbers, though, you need to remove the currency-specific symbols: the dollar signs and commas.
Write a method called currency_to_f that uses the String class's gsub method to remove these symbols. Return the cleaned string as a Float. Add it to the String class definition.
Solution
class String
def currency_to_f
self.gsub('$','').gsub(",",'').to_f
end
end
Examples of use:
puts "$100" + "$200,345"
#=> $100$200,345
puts "$100".currency_to_f + "$200,345".currency_to_f
#=> 200445.0
Mucking with a class
Not only can you add methods to class definitions easily, you can alter existing methods. This is generally not advisable. For example:
class String
def upcase
self.downcase
end
end
"Monday to Sunday".upcase
#=> "monday to sunday"
Luckily, any alterations you make to a class in a given program only exist in that given program. You are not, in other words, altering the class definition for any other program.
More methods to come
That was a large chunk of programming theory to learn (and there is much more to methods and much more about what could go wrong) but we're finally at the point where we start to accomplish complicated tasks.
This is mostly because other programmers have done the hard work for us. But now we know how to benefit from it. The next chapter goes through some practical examples.